Checking terminology
The Terminology accessory lets you find the glossary terms in the source text, and tells you possible mistranslation in the target text. Basically this accessory is used with a glossary corpus. You may use it with other corpora, for example, for quickly checking alternative translation of the whole or a part of the source text.
When you check the Auto Verification option, the accessory will automatically check the terms in the record as it is loaded. Or you can check the terms anytime by clicking Verify button. The Terminology accessory helps you maintain the quality of your translation. It is also a good tool when you review the translation for a client who offers a glossary different from others.
As you see in the clip, you can easily generate a glossary corpus from a list of terms created by a spreadsheet program. The original term list may have more than two language columns. Just like other major CAT tools, the imported glossary can be used with any combination of the languages.
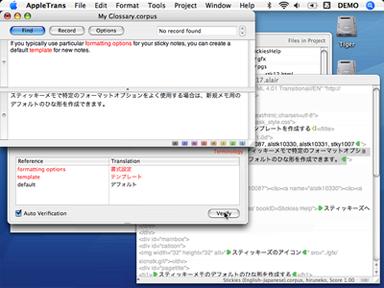
When you check the Auto Verification option, the accessory will automatically check the terms in the record as it is loaded. Or you can check the terms anytime by clicking Verify button. The Terminology accessory helps you maintain the quality of your translation. It is also a good tool when you review the translation for a client who offers a glossary different from others.
As you see in the clip, you can easily generate a glossary corpus from a list of terms created by a spreadsheet program. The original term list may have more than two language columns. Just like other major CAT tools, the imported glossary can be used with any combination of the languages.
posted by hiruneko at 9:44 PM
![]()


6 Comments:
Have you worked at all going from J to E using AppleTrans? I haven't got the glossary function to work very well in that direction (which is really the only direction I do). It just doesn't seem to recognize terms very well.
The sentence matcher as well has trouble going from J>E, but if you turn the match cutoff down to 0.4, you will get some fuzzy matches. Turning the match ratio way down in a glossary corpus doesn't seem to make much difference though. If you are interested, I can paste in some examples and match rates I recorded a while back.
Again, I can't comment on going from English into Japanese, that probably works just fine.
I installed AppleTrans to check all these features, but starting to explore the software is a bit slow without any help files. Where are they supposed to be installed? Neither User's Guide nor any of the links in the AppleTrans Help (Contents, Learn About AppleTrans, Solving Problems) work.
Hi Yak,
I understand your issue in J>E translation. I am sorry but I cannot help you much about it. Here is some background.
AppleTrans matches the sentences word by word instead of character by character as seen in other cat tools. The built-in tokenizer works well for Roman languages, but apparently it is not perfect for some non-Roman languages where there is no explicit separators for words or linguistic units.
Technically it is very difficult to tokenize Japanese text into "words" as you know it. For performance reason, AppleTrans implemented a "character class" tokenizer. It works okay with Japanese sentences mixed with Kanji/Kana/Hiragana/Roman letters, but troubles you matching short strings.
One possible solution for that was to use the Language Analysis Manager API in Mac OS for doing morpheme analysis, but it would cost you much in terms of CPU time. So that is where AppleTrans version 1.x stands.
Hi Mhavu,
AppleTrans Help page is a placeholder. It is there just to enable the menu item linking to Keyboard Shortcuts page.
If the AppleTrans Users Guide menu item does not open the document in Preview application, you may have a problem with your system. Ask for help from others in the AppleTrans SIG.
Actually, you can locate the users guide in the application bundle in the following path:
AppleTrans/Contents/Resources/English.lproj/AppleTrans Users Guide.pdf
Hi Hiruneko,
Ok, I thought it was probably something like that. Not a trivial fix, to be sure...
One more question? Why does sending a translation to the alair file from a corpus (using cntl-s or cntl-e) tend to change the formatting, even when you have it set to not use the corpus' formatting? I notice that if I finish a translation, then select all, do revert, then opt-cmd-t -> translate all, the document's native formatting is preserved. Actually, that's pretty much how I use it these days, but it would be nice if I didn't have to revert then re-translate to preserve the original translation. Is this a buglet, or am I doing something wrong?
Oh no, that is a pretty bad one. I have not realized it until now. That I suppose is another Tiger issue.
I confirmed that the text being inserted has no attributes set. It is then supposed to inherit the attributes from the original text, but takes the default attributes instead.
I will work on it for the future release. Your workaround is really good one for the time being.
Thanks for the report, Yak.
Post a Comment
<< Home